Chapter 12 Graphics with ggplot2
The intention of the ggplot2 package is to provide a comprehensive, grammar-based system for generating graphs in a unified and coherent manner, allowing users to create new and innovative data visualizations. The power of this approach has led ggplot2 to become an important tool for visualizing data using R.
Datasets and Packages Used in this Chapter
singer[in lattice]: It contains the heights and voice parts of singers in the New York Choral Society.mtcars[in base]: It contains automotive details on 32 automobiles.Salaries[in car]: It contains salary information for university professors and was collected to explore gender discrepancies in income.We need the following packages:
ggplot2,car, andgridExtra
packages_needed <- c("ggplot2", "car", "gridExtra")
install.packages(packages_needed)
library(ggplot2)
library(car)
library(gridExtra)12.1 Introduction to ggplot2 Grammer
The ggplot2 package implements a system for creating graphics in R based on a comprehensive and coherent grammar.
- In
ggplot2, plots are created by chaining together functions using the plus (+) sign. Each function modifies the plot created up to that point.
# ggplot() function initializes the plot and specifies
# the data source (mtcars) and variables (wt, mpg) to be used.
# aes() function specify what role each variable will play
ggplot(data=mtcars, aes(x=wt, y=mpg)) +
# geom_point() function specifies the plot type
geom_point() +
# labs() function adds annotations (axis labels and a title)
labs(title="Automobile Data", x="Weight", y="Miles Per Gallon")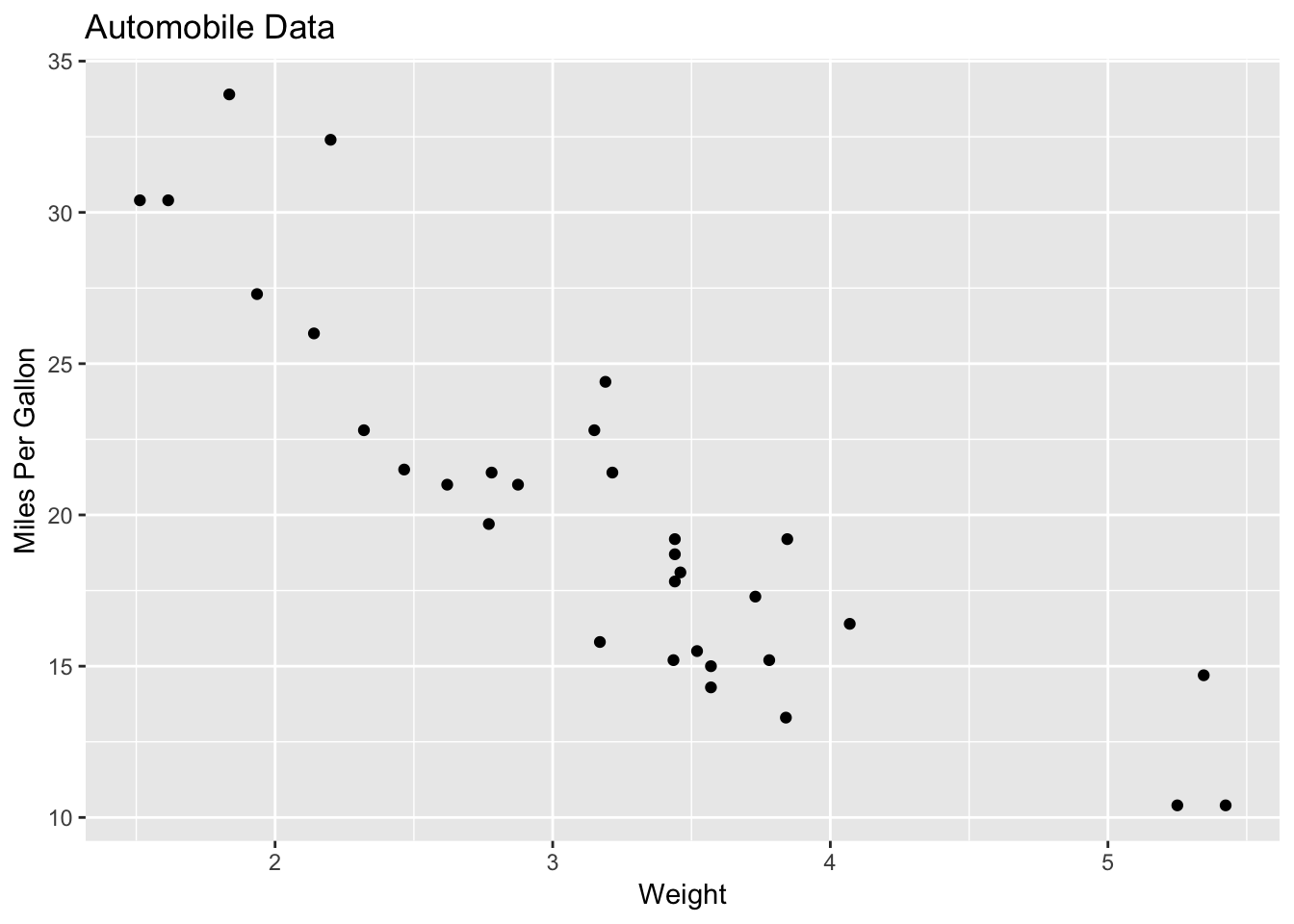
With optional parameters we can modify the plot:
ggplot(data=mtcars, aes(x=wt, y=mpg)) +
# set the point shape to triangles (pch=17), double the
# points’ size (size=2), and render them in blue (color="blue")
geom_point(pch=17, color="blue", size=2) +
# geom_smooth adds a smoothed line.
# a linear fit is requested (method="lm") and a red (color="red")
# dashed (linetype=2) line of size 1 (size=1) is produced.
geom_smooth(method="lm", color="red", linetype=2) +
# labs() function adds annotations (axis labels and a title)
labs(title="Automobile Data", x="Weight", y="Miles Per Gallon")
The ggplot2 package provides methods for grouping and faceting:
Grouping displays two or more groups of observations in a single plot. Groups are usually differentiated by color, shape, or shading.
Faceting displays groups of observations in separate, side-by-side plots.
The ggplot2 package uses factors when defining groups or facets.
Let’s see both grouping and faceting with the mtcars data frame:
# Transform the am, vs, and cyl variables into factors
mtcars$am <- factor(mtcars$am, levels=c(0,1),
labels=c("Automatic", "Manual"))
mtcars$vs <- factor(mtcars$vs, levels=c(0,1),
labels=c("V-Engine", "Straight Engine"))
mtcars$cyl <- factor(mtcars$cyl)
ggplot(data=mtcars, aes(x=hp, y=mpg,
# cyl is the grouping variable
shape=cyl, color=cyl)) +
geom_point(size=3) +
# am and vs are the faceting variables
facet_grid(am~vs) +
labs(title="Automobile Data by Engine Type",
x="Horsepower", y="Miles Per Gallon")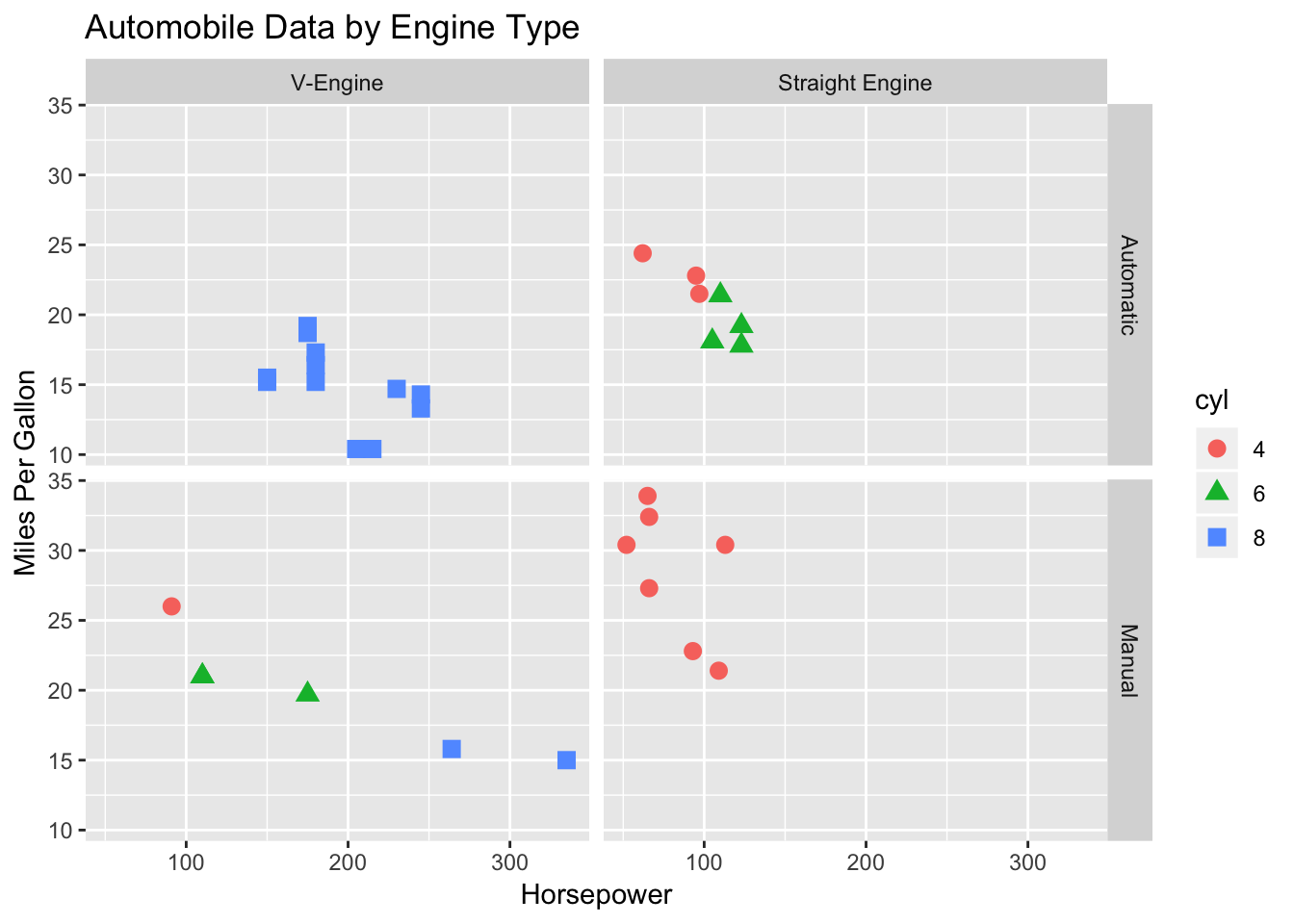 The resulting graph contains separate scatterplots for each combination of transmission type (automatic vs. manual) and engine arrangement (V-engine vs. straight engine). The color and shape of each point indicates the number of engine cylinders in that car.
The resulting graph contains separate scatterplots for each combination of transmission type (automatic vs. manual) and engine arrangement (V-engine vs. straight engine). The color and shape of each point indicates the number of engine cylinders in that car.
12.2 Specifying the Plot Type
Whereas the ggplot() function specifies the data source and variables to be plotted, the geom functions specify how these variables are to be visually represented (using points, bars, lines, and shaded regions).
Most Common geom Functions
| Function | Description | Options |
|---|---|---|
geom_bar |
Bar Chart | color, fill, alpha |
geom_boxplot() |
Box plot | color, fill, alpha, notch, width |
geom_density() |
Density plot | color, fill, alpha, linetype |
geom_histogram() |
Histogram | color, fill, alpha, linetype, binwidth |
geom_hline() |
Horizontal lines | color, alpha, linetype, size |
geom_jitter() |
Jittered points | color, size, alpha, shape |
geom_line() |
Line graph | colorvalpha, linetype, size |
geom_point() |
Scatterplot | color, alpha, shape, size |
geom_rug() |
Rug plot | color, side |
geom_smooth() |
Fitted line | method, formula, color, fill, linetype, size |
geom_text() |
Text annotations | Too many; see the help for this function |
geom_violin() |
Violin plot | color, fill, alpha, linetype |
geom_vline() |
Vertical lines | color, alpha, linetype, size |
Simple examples using singer dataset:
# Load the data
data(singer, package="lattice")
ggplot(singer, aes(x=height)) +
geom_histogram() + # produces a histogram
labs(title="Histogram of Singer Heights",
x="Height", y="Count")## `stat_bin()` using `bins = 30`. Pick better value with `binwidth`.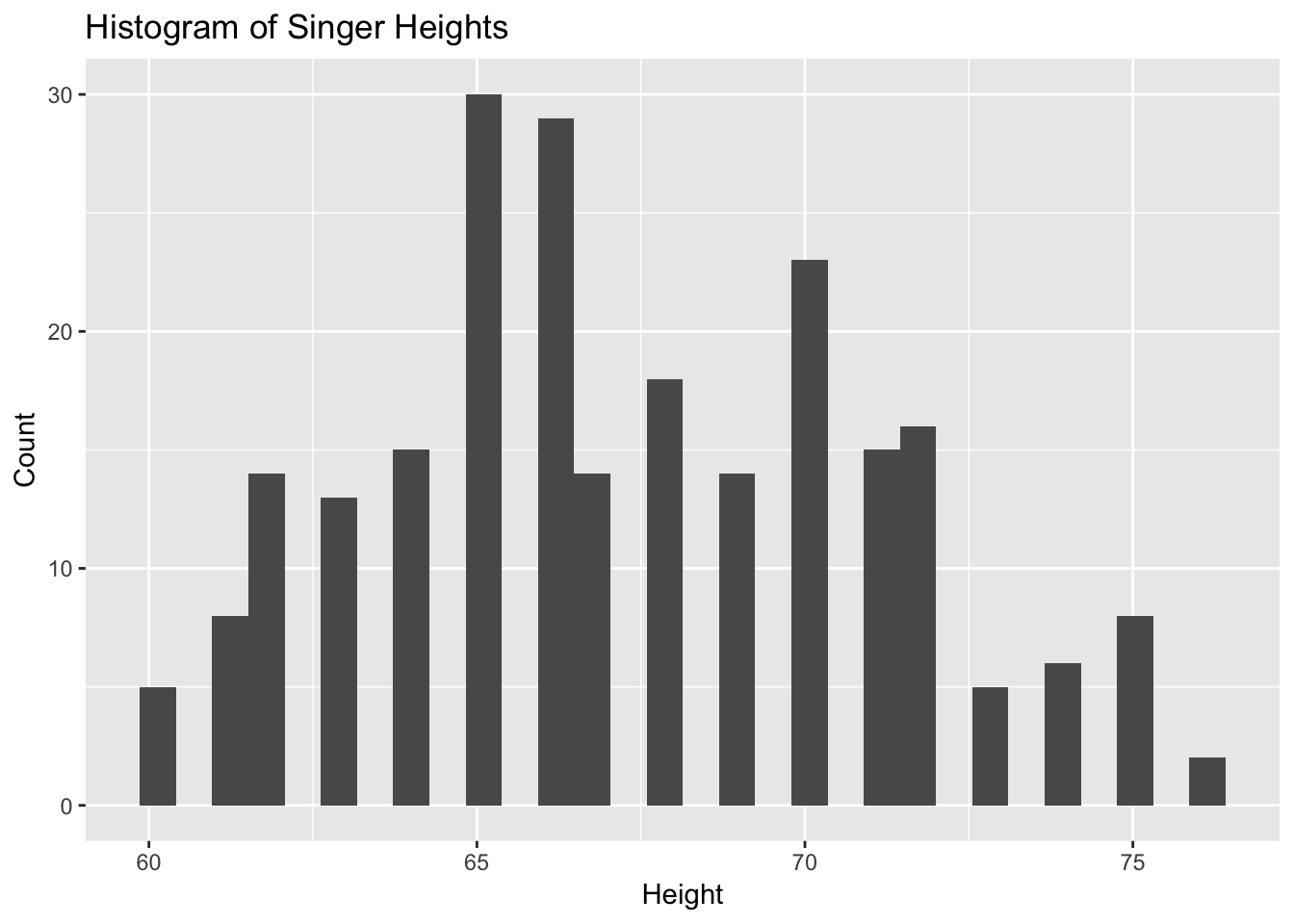
# Load the data
data(singer, package="lattice")
ggplot(singer, aes(x=voice.part, y=height)) +
geom_boxplot() + # produces a boxplot
labs(title="Box plot of Singer Heights by Voice Part",
x="Voice Part", y="Height") We can improve the appearance of plot by using optional
We can improve the appearance of plot by using optional geom functions.
Most Common Options for geom Functions
| Function | Description |
|---|---|
color |
Color of points, lines, and borders around filled regions. |
fill |
Color of filled areas such as bars and density regions. |
alpha |
Transparency of colors, ranging from 0 (fully transparent) to 1 |
| (opaque). | |
linetype |
Pattern for lines (1 = solid, 2 = dashed, 3 = dotted, |
| 4 = dotdash, 5 = longdash, 6 = twodash). | |
size |
Point size and line width. |
shape |
Point shapes (same as pch, with 0 = open square, 1 = open circle, |
| 2 = open triangle, and so on). | |
position |
Position of plotted objects such as bars and points. |
| For bars, “dodge” places grouped bar charts side by side, | |
| “stacked” vertically stacks grouped bar charts, and “fill” | |
| vertically stacks grouped bar charts and standardizes their heights | |
| to be equal. For points, “jitter” reduces point overlap. | |
binwidth |
Bin width for histograms. |
notch |
Indicates whether box plots should be notched (TRUE/FALSE). |
sides |
Placement of rug plots on the graph (“b” = bottom, “l” = left, |
| “t” = top, “r” = right, “bl” = both bottom and left, and so on). | |
width |
Width of box plots. |
Let’s apply some of these options to Salaries dataset:
# Load the data
data(Salaries, package="car")
ggplot(Salaries, aes(x=rank, y=salary)) +
# color of box contents
geom_boxplot(fill="cornflowerblue",
# color of lines and borders and boxplot should be notched
color="black", notch=TRUE) +
# scatterplot + jitter (reduce overlap) + some transparency (alpha=.3)
geom_point(position="jitter", color="blue", alpha=.3) +
# black rug plot
geom_rug(side="l", color="black") +
# add annotations
labs(title="Salaries of College Professors by Rank",
x="Rank", y="Salary")
Note that we combined different geom functions in the same plot. As another example, let’s use singer dataset to combine box plots with violin plots to create a new type of graph:
# Load the data
data(singer, package="lattice")
ggplot(singer, aes(x=voice.part, y=height)) +
geom_violin(fill="lightblue") +
geom_boxplot(fill="lightgreen", width=.2) +
# add annotations
labs(title="A Combined Violin and Box plot of Singer Heights by Voice Part",
x="Voice Part", y="Height")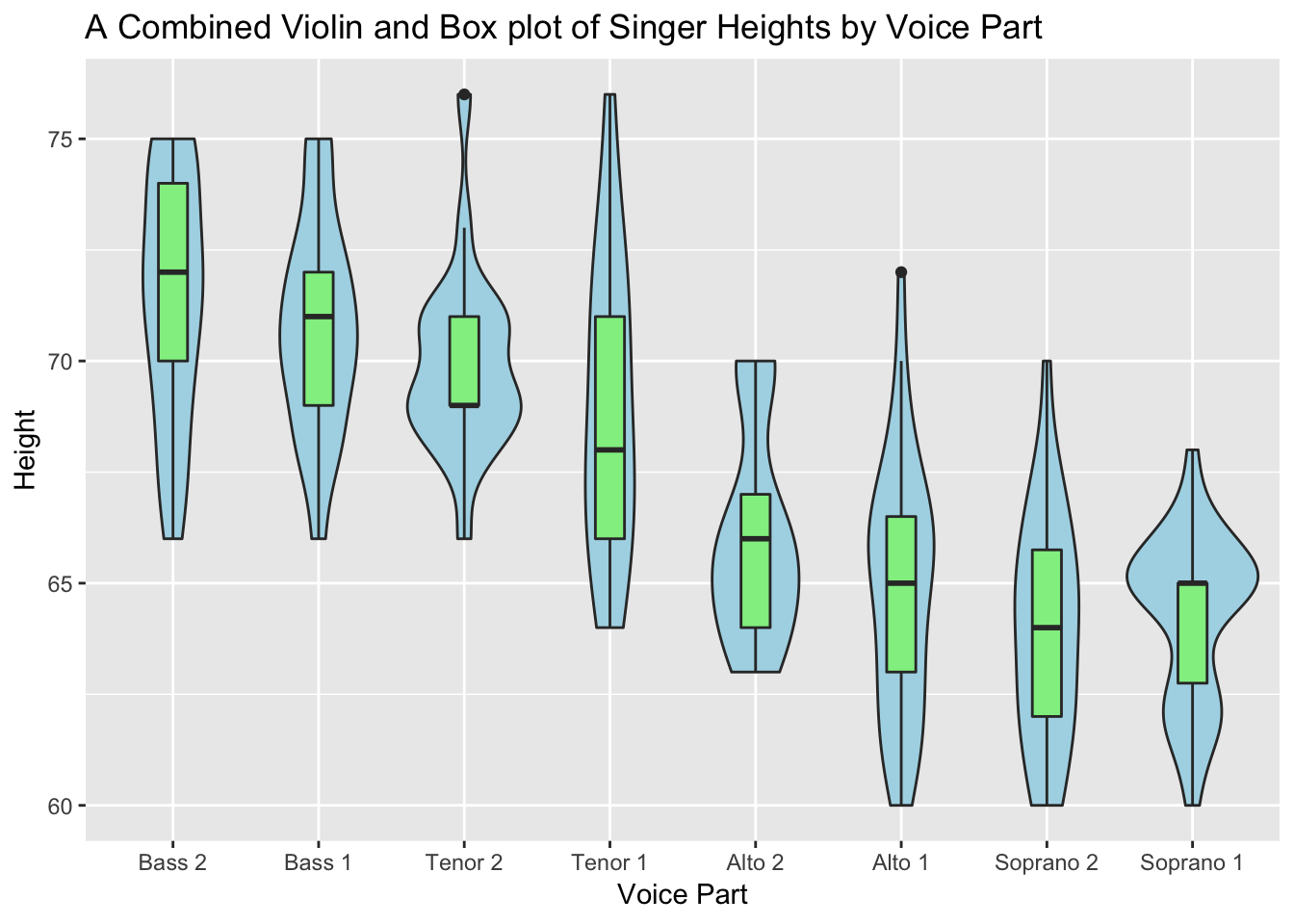 The box plots show the 25th, 50th, and 75th percentile scores for each voice part in the
The box plots show the 25th, 50th, and 75th percentile scores for each voice part in the singer dataframe, along with any outliers. The violin plots provide more visual cues as to the distribution of scores over the range of heights for each voice part.
12.3 Grouping
In order to understand data, it’s often helpful to plot two or more groups of observations on the same graph. In R, the groups are usually defined as the levels of a categorical variable (factor).
Grouping is accomplished in ggplot2 graphs by associating one or more grouping variables with visual characteristics such as shape, color, fill, size, and line type.
The aes() function in the ggplot() statement assigns variables to roles (visual characteristics of the plot), so this is a natural place to assign grouping variables.
Let’s again using Salaries dataset to see how salaries vary by academic rank:
# Load the data
data(Salaries, package="car")
ggplot(data=Salaries, aes(x=salary, fill=rank)) +
geom_density(alpha=.3) +
# add annotations
labs(title="Density Plots of College Professors' Salaries by Rank",
x="Salary", y="Density")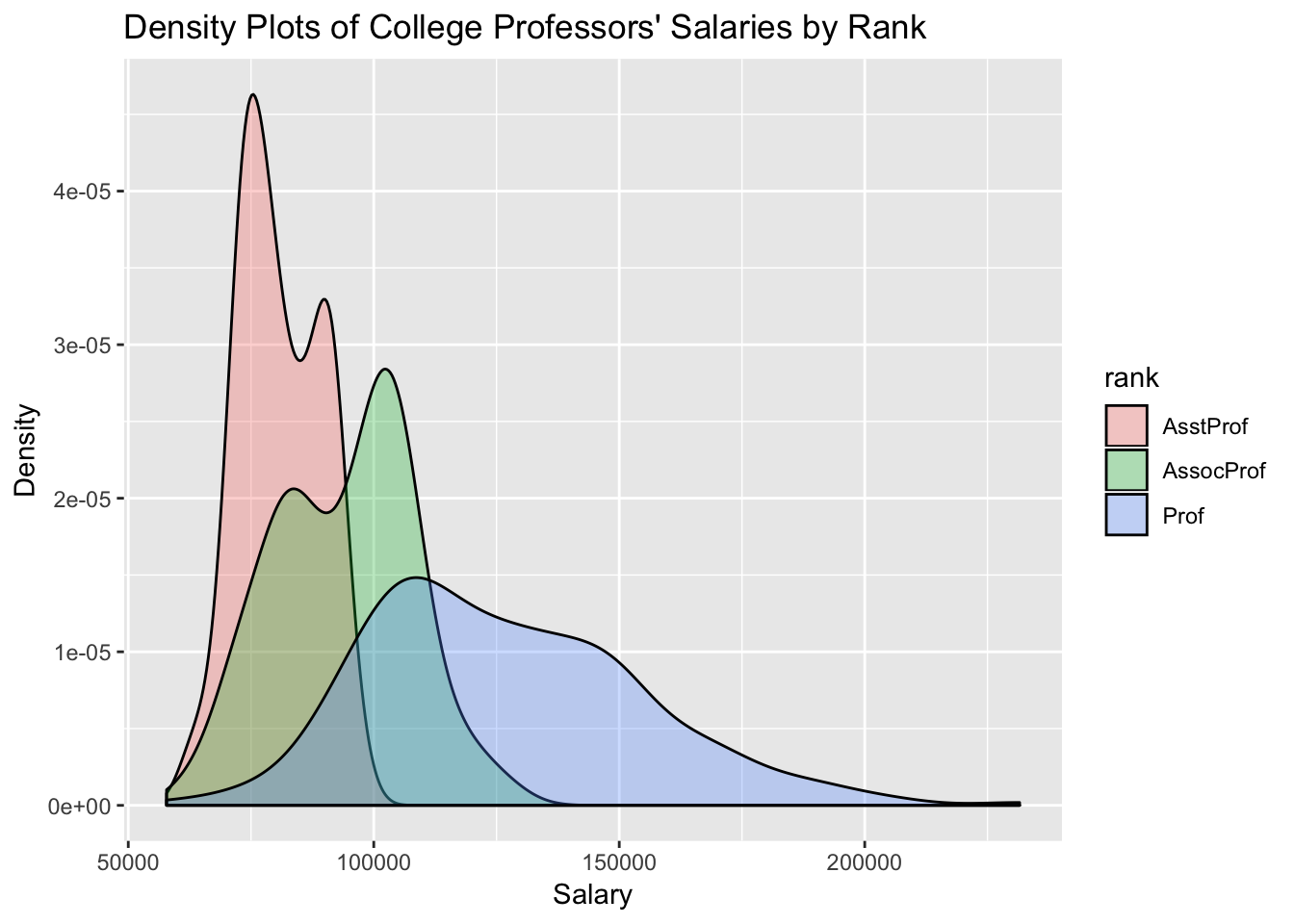 The plot depicts three density curves in the same graph (one for each level of academic rank) and distinguishes them by fill color.
The plot depicts three density curves in the same graph (one for each level of academic rank) and distinguishes them by fill color.
The fills are set to be somewhat transparent (alpha) so that the overlapping curves don’t obscure each other. The colors also com- bine to improve visualization in join areas. The plot is given is figure 19.8. Note that a legend is produced automatically. In section 19.7.2, you’ll learn how to customize the legend generated for grouped data.
Salary increases by rank, but there is significant overlap, with some associate and full professors earning the same as assistant professors. As rank increases, so does the range of salaries. This is especially true for full professors, who have wide variation in their incomes. Placing all three distributions in the same graph facilitates compari- sons among the groups.
Next, let’s plot the relationship between years since Ph.D. and salary, grouping by sex and rank:
# Load the data
data(Salaries, package="car")
# academic rank is represented by point color (color=rank)
# sex is indicated by point shape (shape=sex)
ggplot(Salaries, aes(x=yrs.since.phd, y=salary, color=rank, shape=sex)) +
geom_point() +
# add annotations
labs(title="Scatterplot of Years since Graduation and Salary",
x="Years since PhD", y="Salary")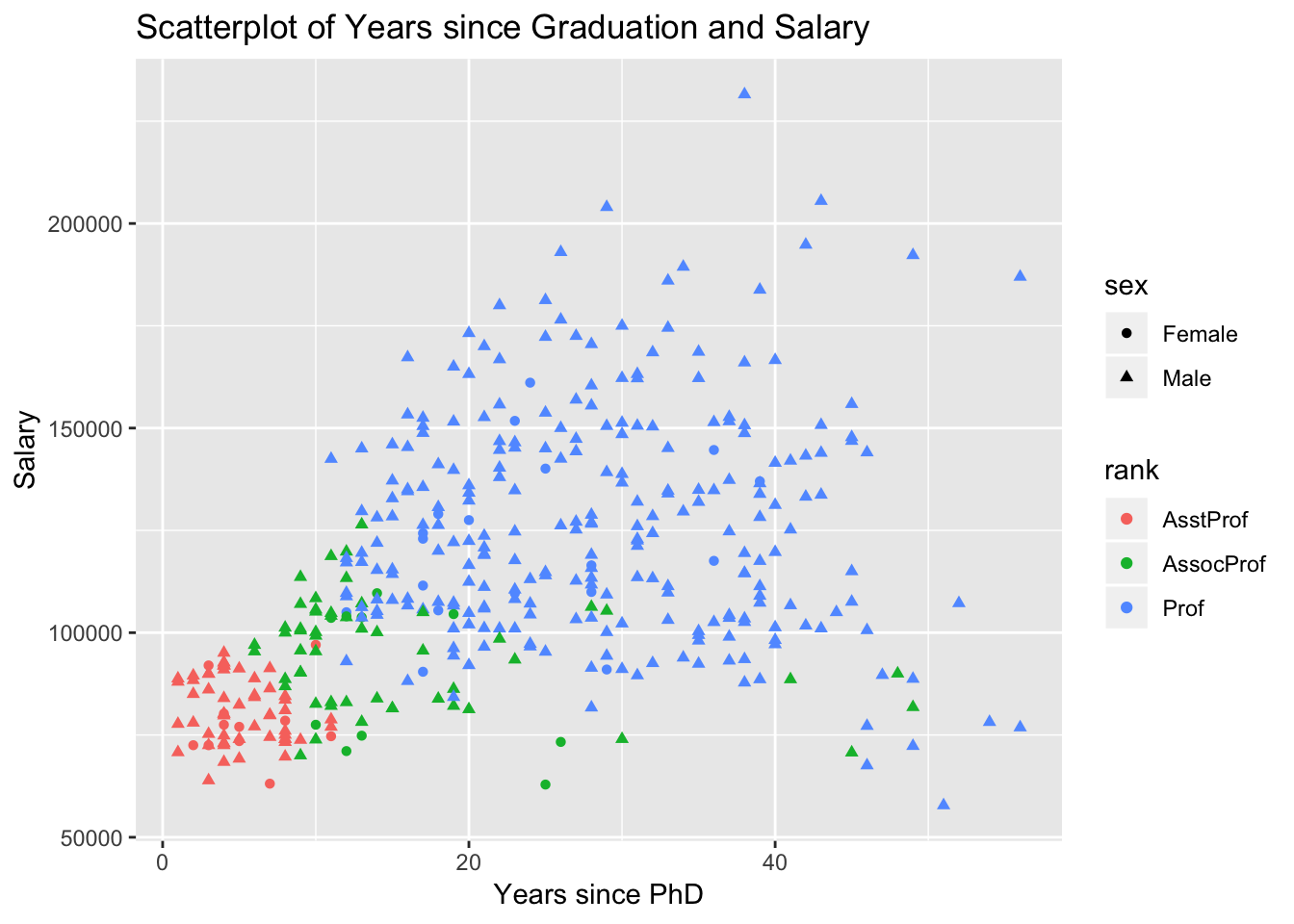
Let’s also visualize the number of professors by rank and sex using a grouped bar chart:
# Load the data
data(Salaries, package="car")
ggplot(Salaries, aes(x=rank, fill=sex)) +
geom_bar(position="stack") + labs(title='position="stack"')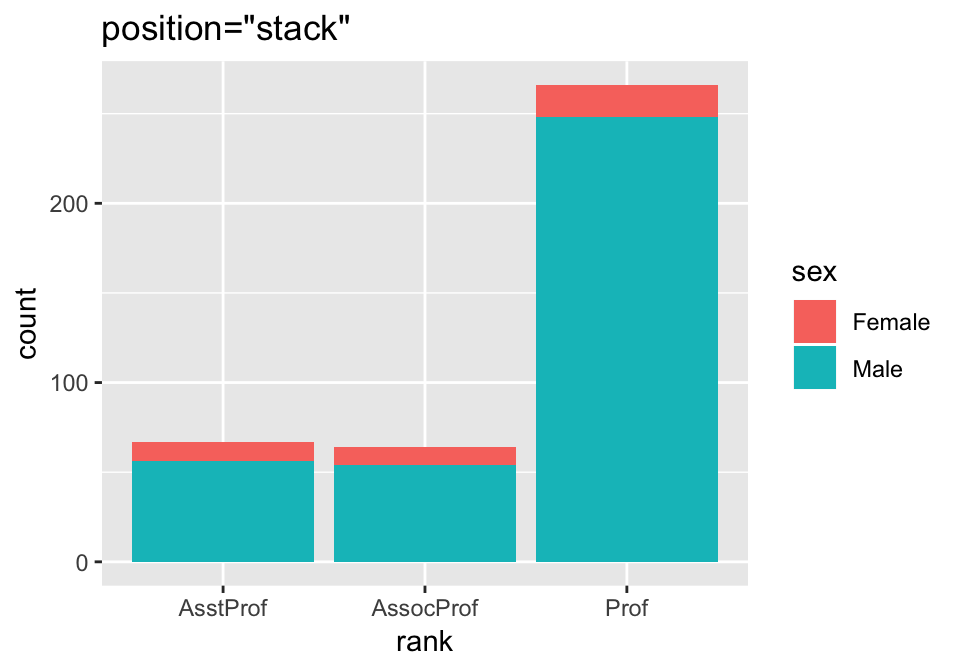
ggplot(Salaries, aes(x=rank, fill=sex)) +
geom_bar(position="dodge") + labs(title='position="dodge"')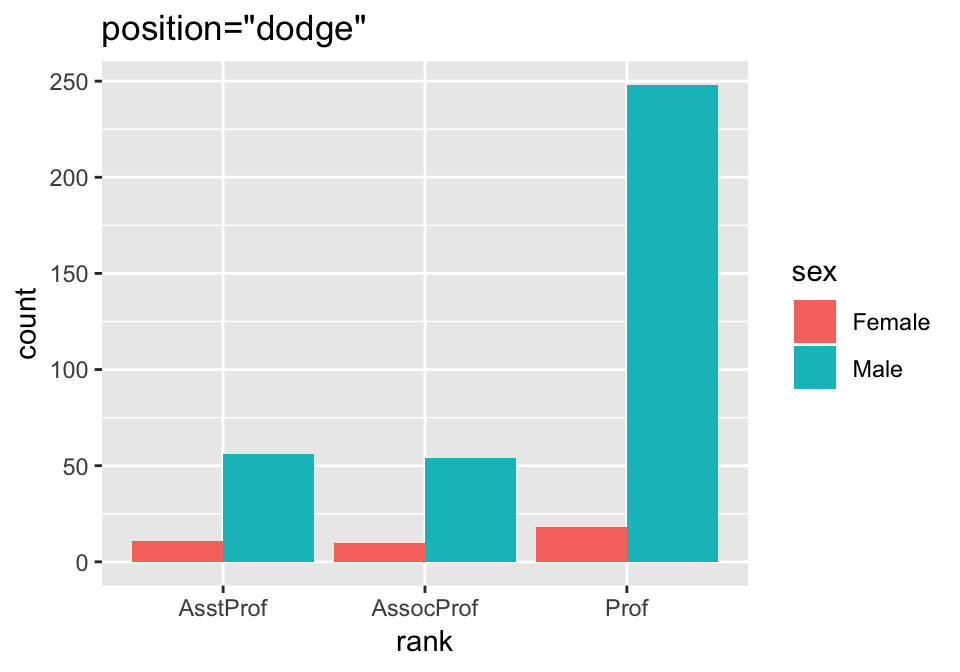
ggplot(Salaries, aes(x=rank, fill=sex)) +
geom_bar(position="fill") + labs(title='position="fill"') +
labs(y="Proportion")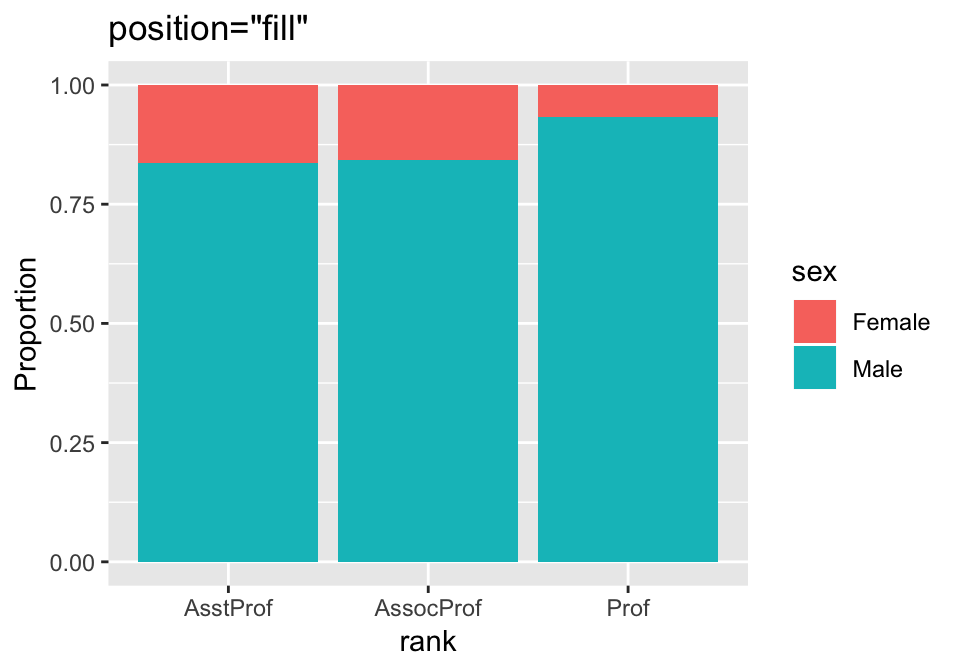
Options can be used in different ways, depending on whether they occur inside or outside the aes() function. Look at the following examples:
# Load the data
data(Salaries, package="car")
# sex is a variable represented by fill color in the bar graph
ggplot(Salaries, aes(x=rank, fill=sex)) +
geom_bar()
# each bar is filled with the color red
ggplot(Salaries, aes(x=rank)) +
geom_bar(fill="red")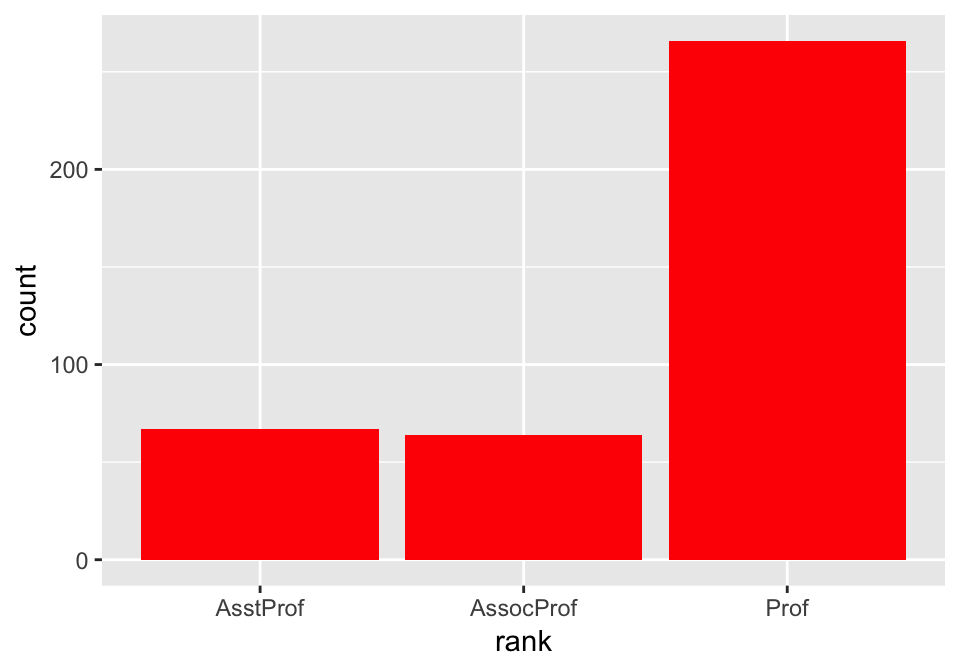
# ggplot2 assumes that "red" is the name of a variable
ggplot(Salaries, aes(x=rank, fill="red")) +
geom_bar()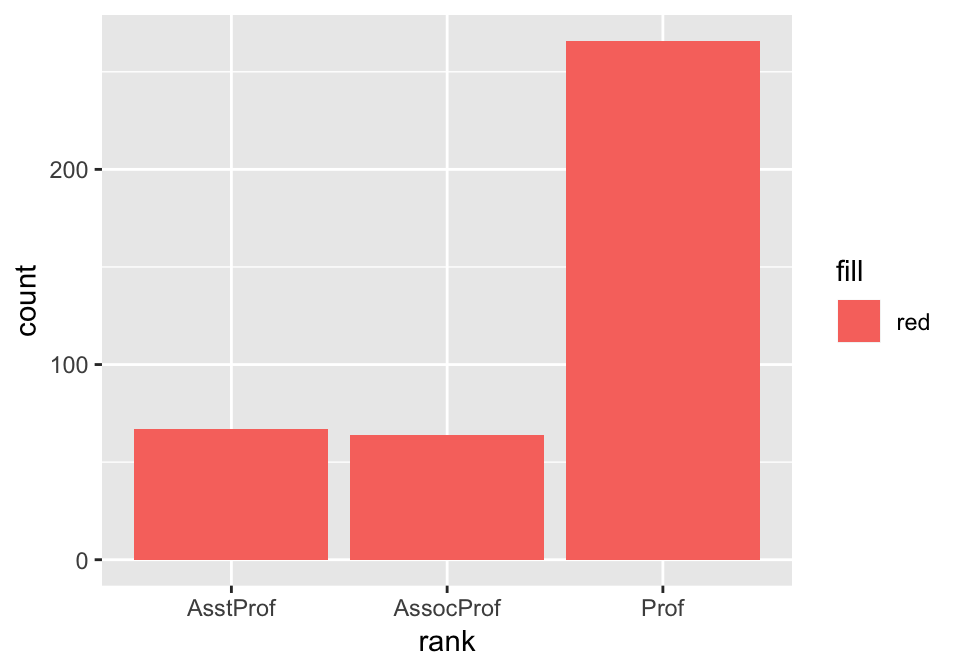 In general, variables should go inside
In general, variables should go inside aes(), and assigned constants should go outside aes().
12.4 Faceting
Sometimes relationships are clearer if groups appear in side-by-side graphs rather than overlapping in a single graph. You can create trellis graphs (called faceted graphs in ggplot2) using the facet_wrap() and facet_grid() functions. The syntax is given in table below, where var, rowvar, and colvar are factors.
| Syntax | Description |
|---|---|
facet_wrap(~var, ncol=n) |
Separate plots for each level of var arranged into n columns |
facet_grid(rowvar~colvar) |
Separate plots for each combination of rowvar and colvar, where |
| rowvar represents rows and colvar represents columns | |
facet_grid(rowvar~.) |
Separate plots for each level of rowvar, arranged as a single column |
facet_grid(.~colvar) |
Separate plots for each level of colvar, arranged as a single row |
Going back to the choral example, you can a faceted graph using the following code:
data(singer, package="lattice")
ggplot(data=singer, aes(x=height)) +
geom_histogram() +
facet_wrap(~voice.part, nrow=4)## `stat_bin()` using `bins = 30`. Pick better value with `binwidth`.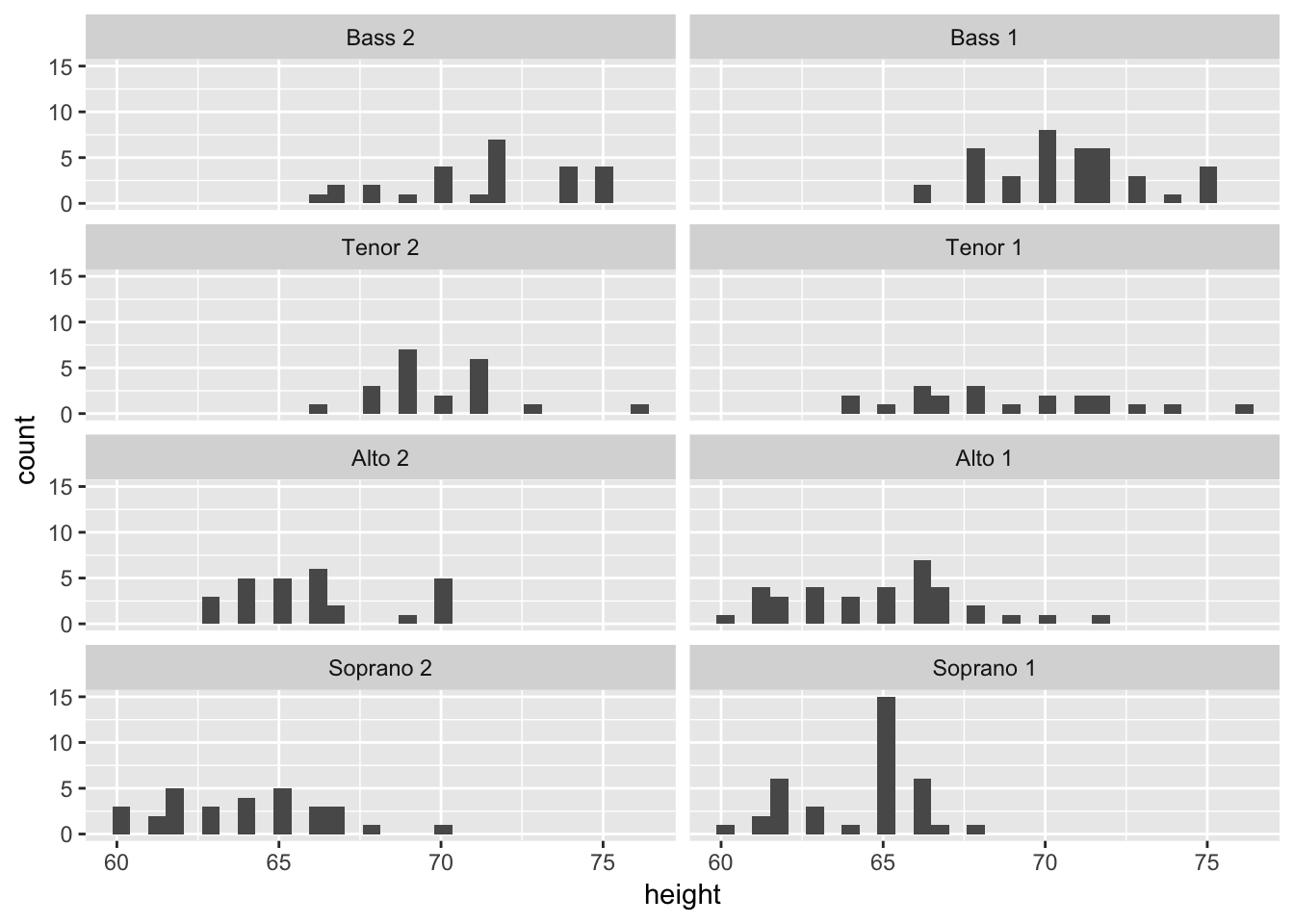 The resulting plot displays the distribution of singer heights by voice part. Separating the eight distributions into their own small, side-by-side plots makes them easier to compare.
The resulting plot displays the distribution of singer heights by voice part. Separating the eight distributions into their own small, side-by-side plots makes them easier to compare.
As a second example, let’s create a graph that has faceting and grouping:
ggplot(Salaries, aes(x=yrs.since.phd, y=salary, color=rank,
shape=rank)) +
geom_point() +
facet_grid(.~sex)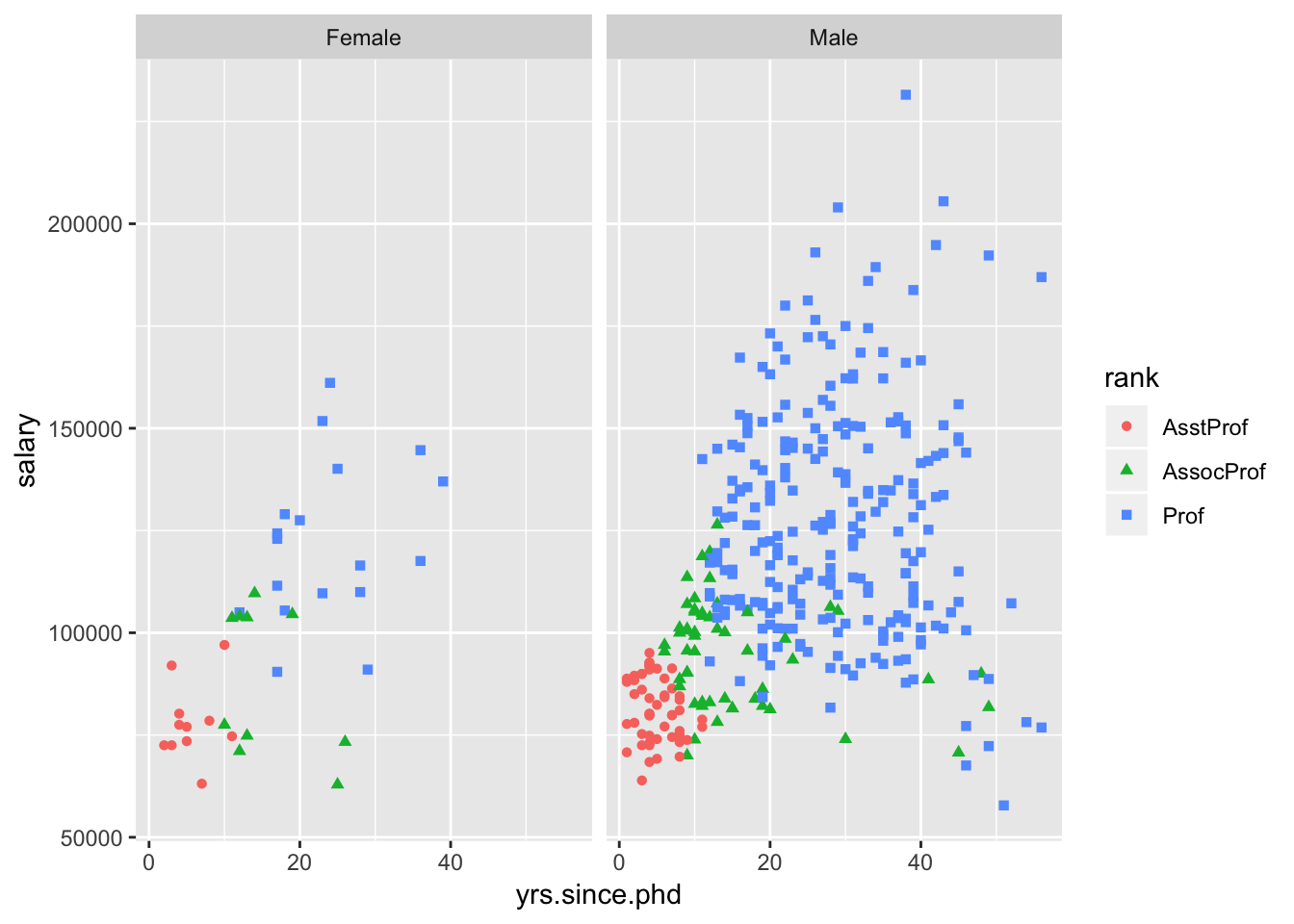
Finally, try displaying the height distribution of choral members in the singer dataset separately for each voice part, using kernel-density plots arranged horizontally. Give each a different color. One solution is as follows:
data(singer, package="lattice")
ggplot(data=singer, aes(x=height, fill=voice.part)) +
geom_density() +
facet_grid(voice.part~.)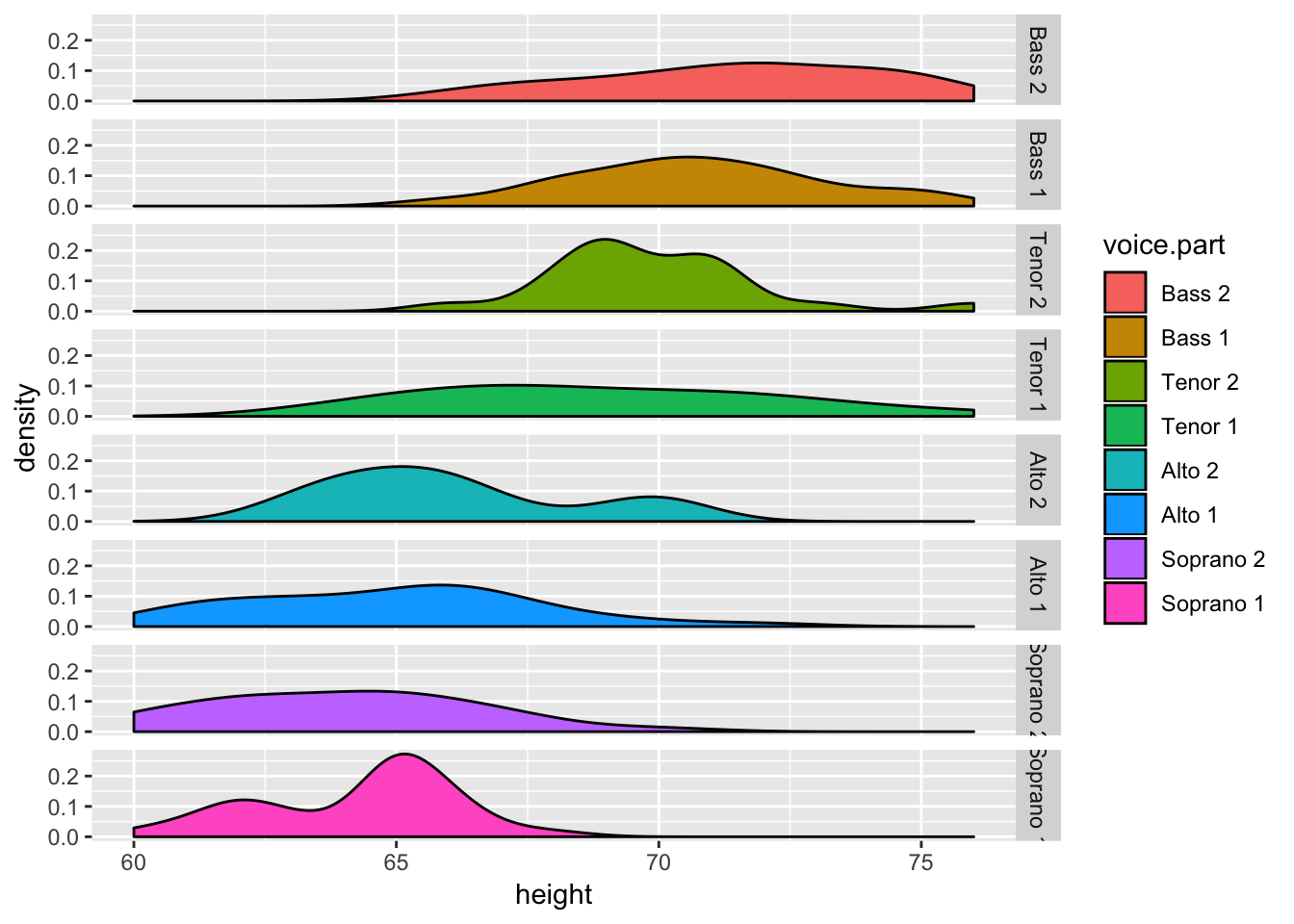 Note that the horizontal arrangement facilitates comparisons among the groups. The colors aren’t strictly necessary, but they can aid in distinguishing the plots.
Note that the horizontal arrangement facilitates comparisons among the groups. The colors aren’t strictly necessary, but they can aid in distinguishing the plots.
NOTE You may wonder why the legend for the density plots includes a black diagonal line through each box. Because you can control both the fill color of the density plots and their border colors (black by default), the legend displays both.
12.5 Adding smoothed lines
The ggplot2 package contains a wide range of functions for calculating statistical summaries that can be added to graphs. These include functions for binning data and calculating densities, contours, and quantiles. This section looks at methods for add- ing smoothed lines (linear, nonlinear, and nonparametric) to scatter plots.
You can use the geom_smooth() function to add a variety of smoothed lines and confidence regions.
| Option | Description |
|---|---|
method= |
Smoothing function to use. Allowable values include |
lm, glm, smooth, rlm, and gam, for linear, generalized linear, |
|
| loess, robust linear, and generalized additive modeling, respectively. | |
smooth is the default. |
|
formula= |
Formula to use in the smoothing function. Examples include |
y~x (the default), |
|
y~log(x), y~poly(x,n) for an nth degree polynomial fit, and |
|
y~ns(x,n) for a spline fit with n degrees of freedom. |
|
se |
Plots confidence intervals (TRUE/FALSE). TRUE is the default. |
level |
Level of confidence interval to use (95% by default). |
fullrange |
Specifies whether the fit should span the full range of the plot (TRUE) |
or just the data (FALSE). FALSE is the default. |
Using the Salaries dataset, let’s first examine the relationship between years since obtaining a Ph.D. and faculty salaries. In this example, you’ll use a nonparametric smoothed line (loess) with 95% confidence limits. Ignore sex and rank for now:
data(Salaries, package="car")## Warning in data(Salaries, package = "car"): data set 'Salaries' not foundggplot(data=Salaries, aes(x=yrs.since.phd, y=salary)) +
geom_smooth() +
geom_point()## `geom_smooth()` using method = 'loess' and formula 'y ~ x'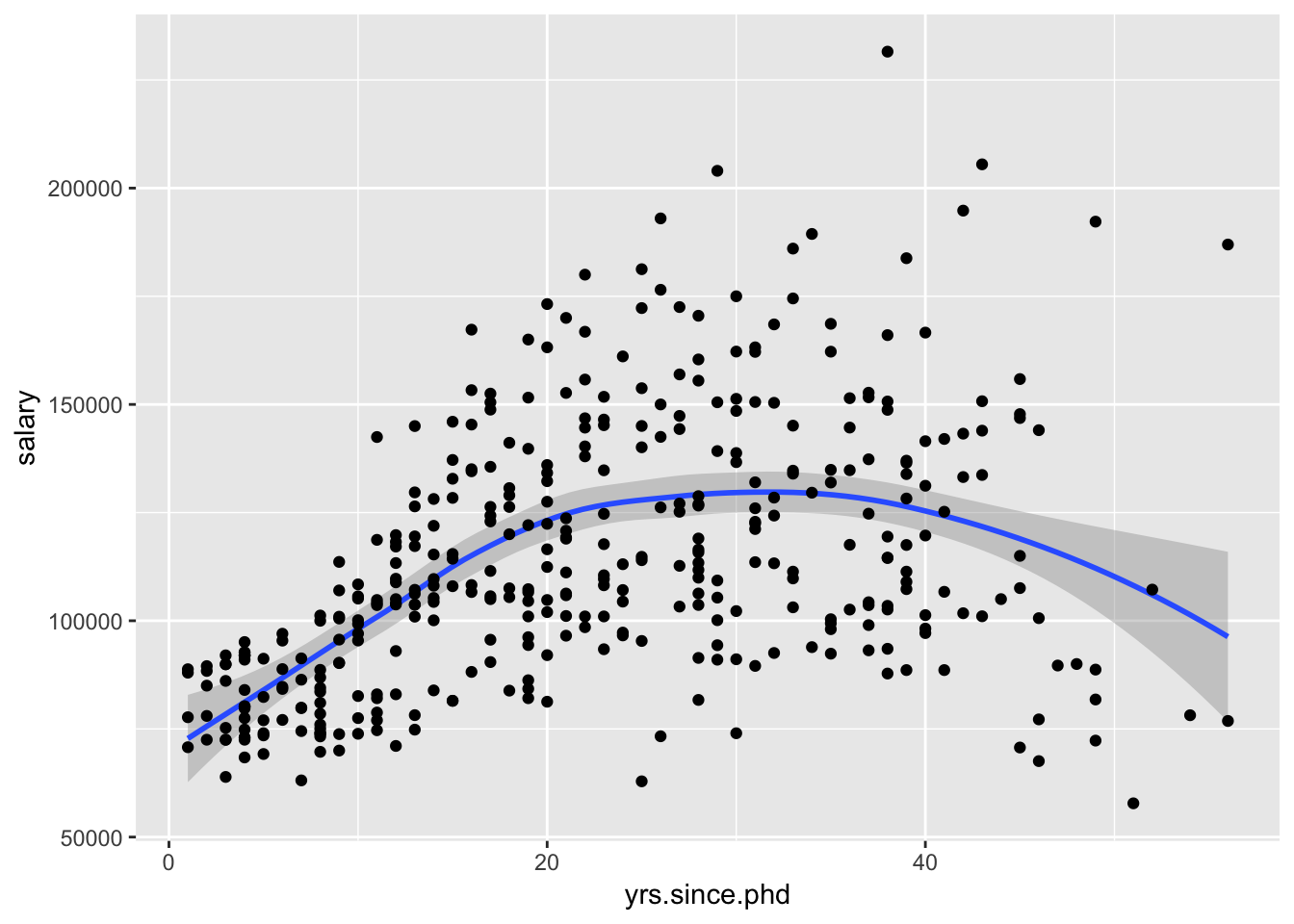 The plot suggests that the relationship between experience and salary isn’t linear, at least when considering faculty who graduated many years ago.
The plot suggests that the relationship between experience and salary isn’t linear, at least when considering faculty who graduated many years ago.
Next, let’s fit a quadratic polynomial regression (one bend) separately by gender:
ggplot(data=Salaries, aes(x=yrs.since.phd, y=salary,
linetype=sex, shape=sex, color=sex)) +
geom_smooth(method=lm, formula=y~poly(x,2),
se=FALSE, size=1) +
geom_point(size=2)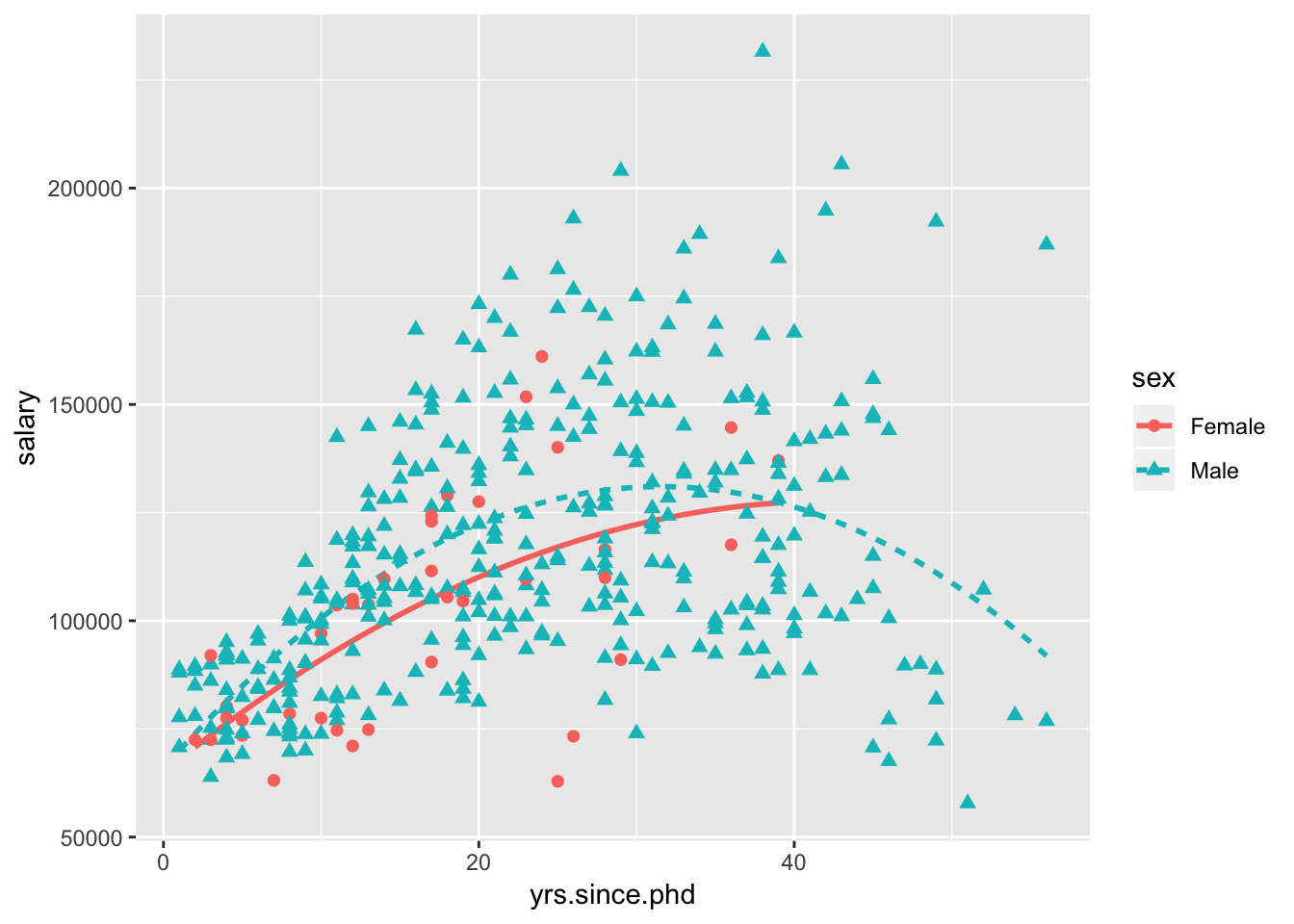 The confidence limits are suppressed to simplify the graph (se=FALSE). Genders are differentiated by color, symbol shape, and line type.
The confidence limits are suppressed to simplify the graph (se=FALSE). Genders are differentiated by color, symbol shape, and line type.
The curve for males appears to increase from 0 to about 30 years and then decrease. The curve for women rises from 0 to 40 years. No women in the dataset received their degree more than 40 years ago. For most of the range where both genders have data, men have received higher salaries.
Stat functions
In this section, you’ve added smoothed lines to scatter plots. The ggplot2 package contains a wide range of statistical functions (called stat functions) for calculating the quantities necessary to produce a variety of data visualizations. Typically, geom functions call the stat functions implicitly, and you won’t need to deal with them directly. But it’s useful to know they exist. Each stat function has help pages that can aid you in understanding how the geoms work.
For example, the geom_smooth() function relies on the stat_smooth() function to calculate the quantities needed to plot a fitted line and its confidence limits. The help page for geom_smooth() is sparse, but the help page for stat_smooth() contains a wealth of useful information. When exploring how a geom works and what options are available, be sure to check out both the geom function and its related stat function(s).
12.6 Modifying the appearance of ggplot2 graphs
In chapter 3, you saw how to customize base graphics using graphical parameters placed in the par() function or specific plotting functions. Unfortunately, changing base graphics parameters has no effect on ggplot2 graphs. Instead, the ggplot2 package offers specific functions for changing the appearance of its graphs.
In this section, we’ll look at several functions that allow you to customize the appearance of ggplot2 graphs. You’ll learn how to customize the appearance of axes (limits, tick marks, and tick mark labels), the placement and content of legends, and the colors used to represent variable values. You’ll also learn how to create custom themes (allowing you to add a consistent look and feel to your graphs) and arrange several plots into a single graph.
12.6.1 Axes
The ggplot2 package automatically creates plot axes with tick marks, tick mark labels, and axis labels. Often they look fine, but occasionally you’ll want to take greater con- trol over their appearance. You’ve already seen how to use the labs() function to add a title and change the axis labels. In this section, you’ll customize the axes themselves. Table 19.6 contains functions that are useful for customizing axes.
| Function | Options |
|---|---|
scale_x_continuous() |
breaks= specifies tick marks, labels= specifies labels |
| for tick marks, and limits= controls the range of the | |
values displayed. scale_y_continuous() works similarly. |
|
scale_x_discrete() |
breaks= places and orders the levels of a factor, |
| labels= specifies the labels for these levels, and | |
| limits= indicates which levels should be displayed. | |
scale_y_discrete() works similarly. |
|
coord_flip() |
Reverses the x and y axes. |
As you can see, ggplot2 functions distinguish between the x- and y-axes and whether an axis represents a continuous or discrete (factor) variable.
Let’s apply these functions to a graph with grouped box plots for faculty salaries by rank and sex. The code is as follows:
# figure 19.16
data(Salaries,package="car")## Warning in data(Salaries, package = "car"): data set 'Salaries' not foundggplot(data=Salaries, aes(x=rank, y=salary, fill=sex)) +
geom_boxplot() +
scale_x_discrete(breaks=c("AsstProf", "AssocProf", "Prof"),
labels=c("Assistant\nProfessor",
"Associate\nProfessor",
"Full\nProfessor")) + scale_y_continuous(breaks=c(50000, 100000, 150000, 200000),
labels=c("$50K", "$100K", "$150K", "$200K")) +
labs(title="Faculty Salary by Rank and Sex", x="", y="")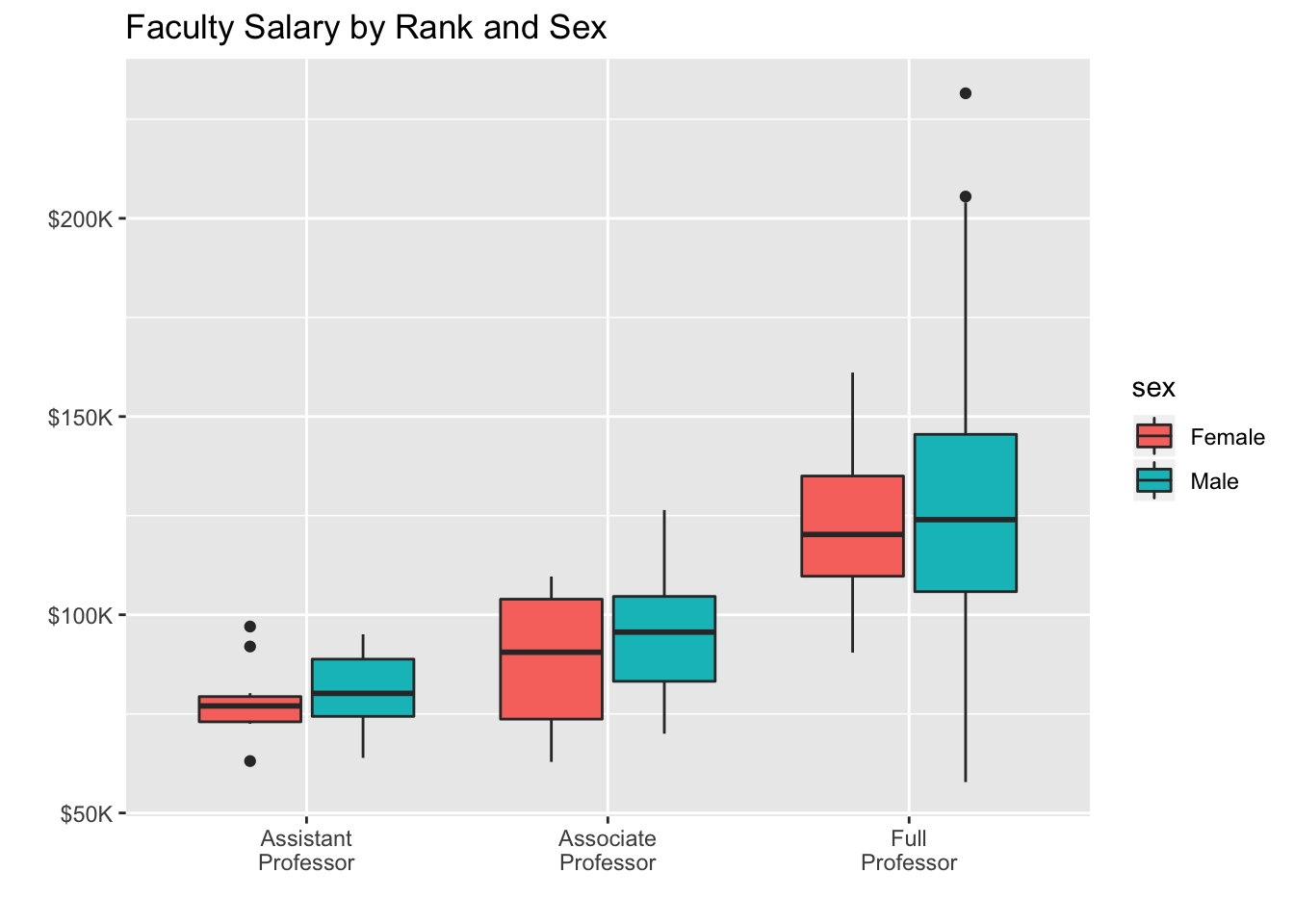 Clearly, average income goes up with rank, and men make more than women within each teaching rank. (For a more complete picture, try controlling for years since Ph.D.)
Clearly, average income goes up with rank, and men make more than women within each teaching rank. (For a more complete picture, try controlling for years since Ph.D.)
12.6.2 Legends
Legends are guides that indicate how visual characteristics like color, shape, and size represent qualities of the data. The ggplot2 package generates legends automatically, and in many cases they suffice quite well. At other times, you may want to customize them. The title and placement are the most commonly customized characteristics.
When modifying a legend’s title, you have to take into account whether the legend is based on color, fill, size, shape, or a combination. In figure 19.16, the legend represents the fill aesthetic (as you can see in the aes() function), so you can change the title by adding fill="mytitle" to the labs() function.
The placement of the legend is controlled by the legend.position option in the theme() function. Possible values include "left", "top", "right"(the default), and "bottom". Alternatively, you can specify a two-element vector that gives the position within the graph. Let’s modify the graph in figure 19.16 so that the legend appears in the upper-left corner and the title is changed from sex to Gender. This can be accomplished with the following code:
data(Salaries,package="car")## Warning in data(Salaries, package = "car"): data set 'Salaries' not foundggplot(data=Salaries, aes(x=rank, y=salary, fill=sex)) +
geom_boxplot() +
scale_x_discrete(breaks=c("AsstProf", "AssocProf", "Prof"),
labels=c("Assistant\nProfessor",
"Associate\nProfessor","Full\nProfessor")) + scale_y_continuous(breaks=c(50000, 100000, 150000, 200000),
labels=c("$50K", "$100K", "$150K", "$200K")) +
labs(title="Faculty Salary by Rank and Gender", x="", y="", fill="Gender") +
theme(legend.position=c(.1,.8))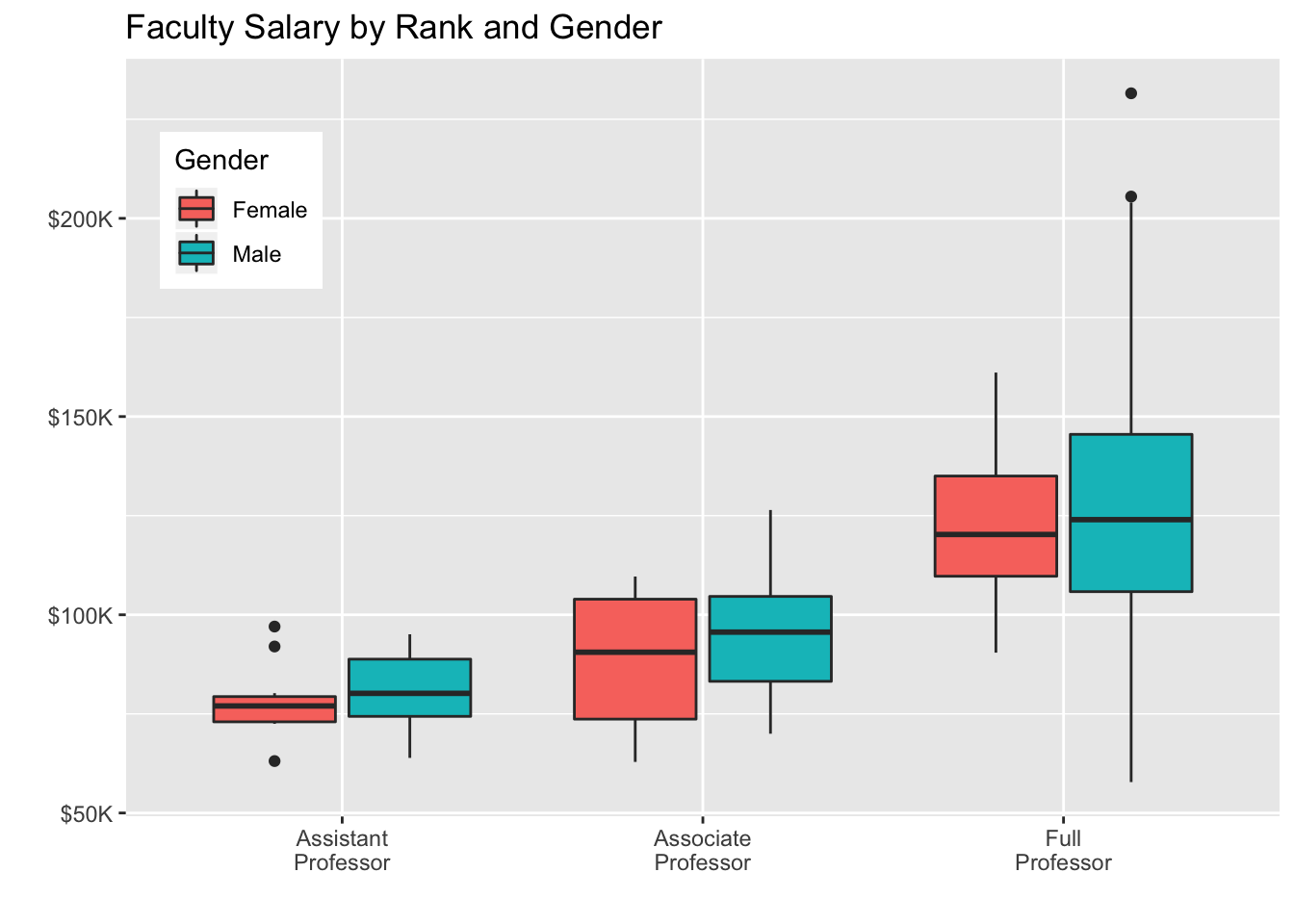 In this example, the upper-left corner of the legend was placed 10% from the left edge and 80% from the bottom edge of the graph. If you want to omit the legend, use legend.position=“none”. The theme() function can change many aspects of a ggplot2 graph’s appearance.
In this example, the upper-left corner of the legend was placed 10% from the left edge and 80% from the bottom edge of the graph. If you want to omit the legend, use legend.position=“none”. The theme() function can change many aspects of a ggplot2 graph’s appearance.
12.6.3 Scales
The ggplot2 package uses scales to map observations from the data space to the visual space. Scales apply to both continuous and discrete variables. In figure 19.15, a continuous scale was used to map the numeric values of the yrs.since.phd variable to distances along the x-axis and map the numeric values of the salary variable to distances along the y-axis.
Continuous scales can map numeric variables to other characteristics of the plot. Consider the following code:
ggplot(mtcars, aes(x=wt, y=mpg, size=disp)) +
geom_point(shape=21, color="black", fill="cornsilk") +
labs(x="Weight", y="Miles Per Gallon",
title="Bubble Chart", size="Engine\nDisplacement")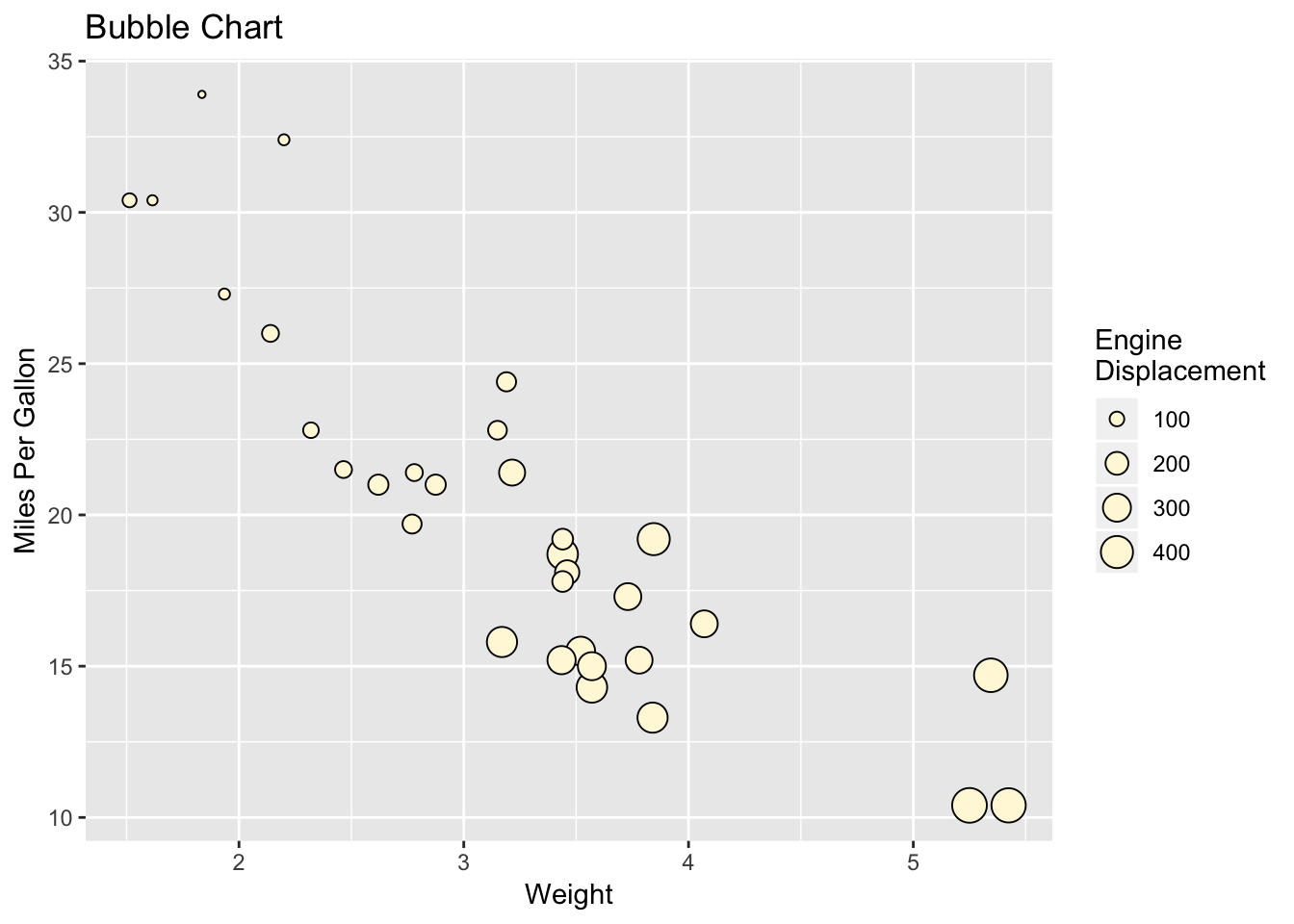 The
The aes() parameter size=disp generates a scale for the continuous variable disp (engine displacement) and uses it to control the size of the points. The result is the bubble chart presented in the figure above. The graph shows that auto mileage decreases with both weight and engine displacement.
In the discrete case, you can use a scale to associate visual cues (for example, color, shape, line type, size, and transparency) with the levels of a factor. The code
# Figure 19.19
data(Salaries, package="car")## Warning in data(Salaries, package = "car"): data set 'Salaries' not foundggplot(data=Salaries, aes(x=yrs.since.phd, y=salary, color=rank)) +
scale_color_manual(values=c("orange", "olivedrab", "navy")) + geom_point(size=2)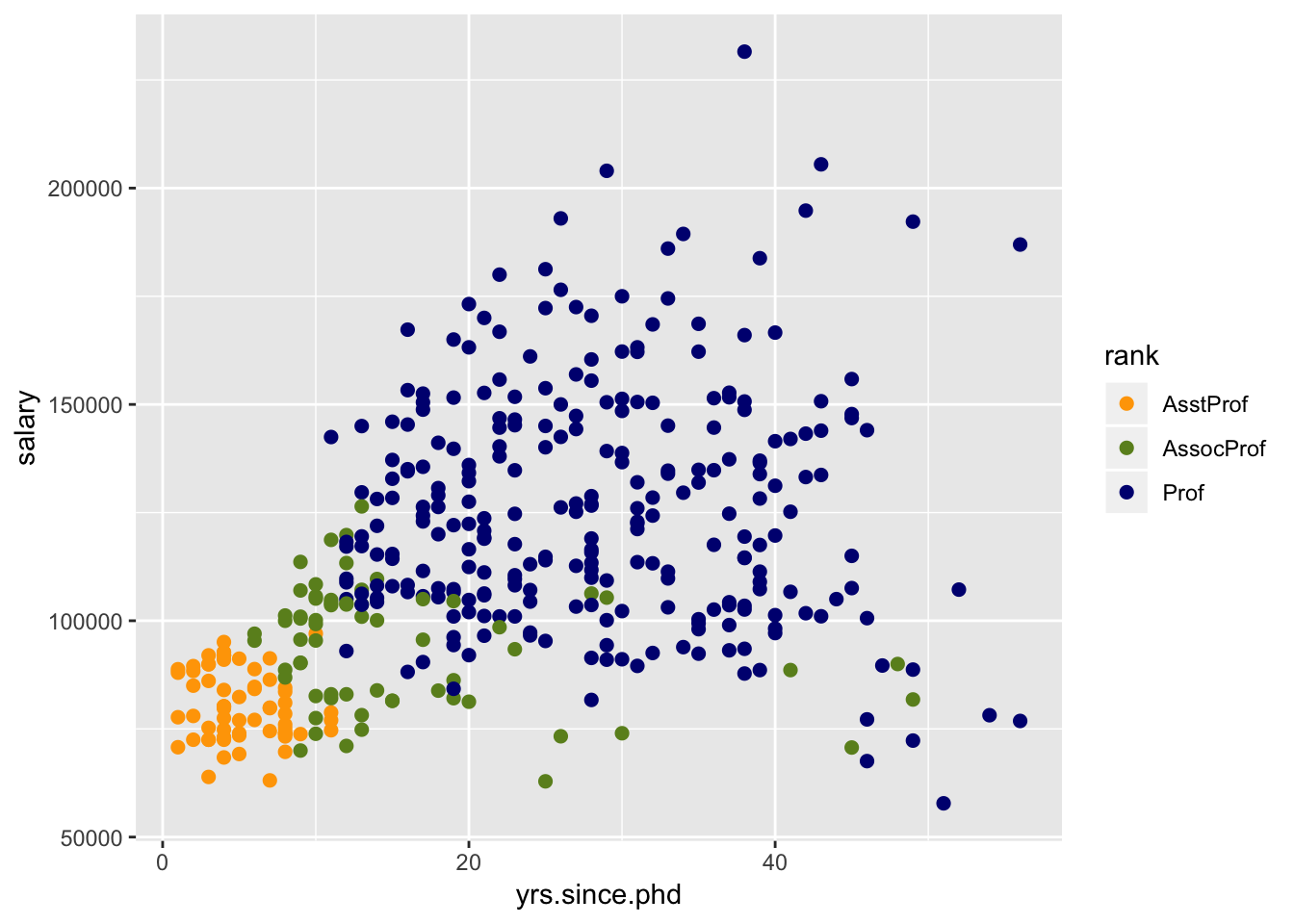 uses the
uses the scale_color_manual() function to set the point colors for the three aca- demic ranks. The results are displayed in figure 19.19.
If you’re color challenged like I am (does purple go with orange?), you can use color presets via the scale_color_brewer() and scale_fill_brewer() functions to specify attractive color sets. For example, try the code
ggplot(data=Salaries, aes(x=yrs.since.phd, y=salary, color=rank)) +
scale_color_brewer(palette="Set1") + geom_point(size=2)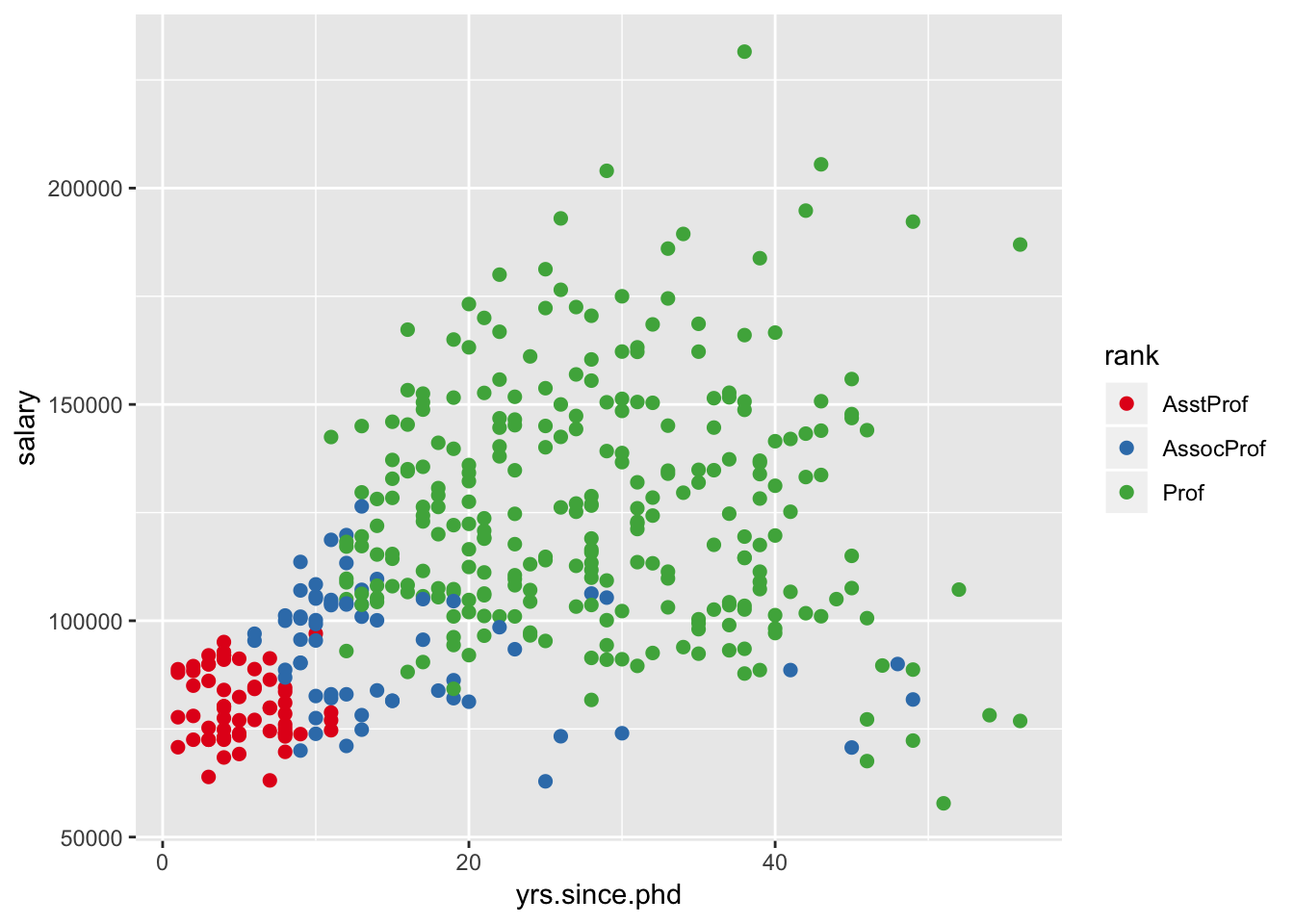 and see what you get. Replacing
and see what you get. Replacing palette="Set1" with another value (such as "Set2", "Set3", "Pastel1", "Pastel2", "Paired", "Dark2", or "Accent") will result in a different color scheme. To see the available color sets, use
library(RColorBrewer)
display.brewer.all()to generate a display. For more information, see help(scale_color_brewer) and the ColorBrewer homepage (http://colorbrewer2.org).
The concept of scales is general in ggplot2. Although we won’t cover this further, you can control the characteristics of scales. See the functions that have scale_ in their name for more details.
12.6.4 Themes
You’ve seen several methods for modifying specific visual elements of ggplot2 graphs. Themes allow you to control the overall appearance of these graphs. Options in the theme() function let you change fonts, backgrounds, colors, gridlines, and more. Themes can be used once or saved and applied to many graphs. Consider the following:
data(Salaries, package="car")
mytheme <- theme(plot.title=element_text(face="bold.italic",
size="14", color="brown"),
axis.title=element_text(face="bold.italic",
size=10, color="brown"),
axis.text=element_text(face="bold", size=9,
color="darkblue"),
panel.background=element_rect(fill="white",
color="darkblue"),
panel.grid.major.y=element_line(color="grey",
linetype=1),
panel.grid.minor.y=element_line(color="grey",
linetype=2),
panel.grid.minor.x=element_blank(),
legend.position="top")
ggplot(Salaries, aes(x=rank, y=salary, fill=sex)) +
geom_boxplot() +
labs(title="Salary by Rank and Sex", x="Rank", y="Salary") +
mytheme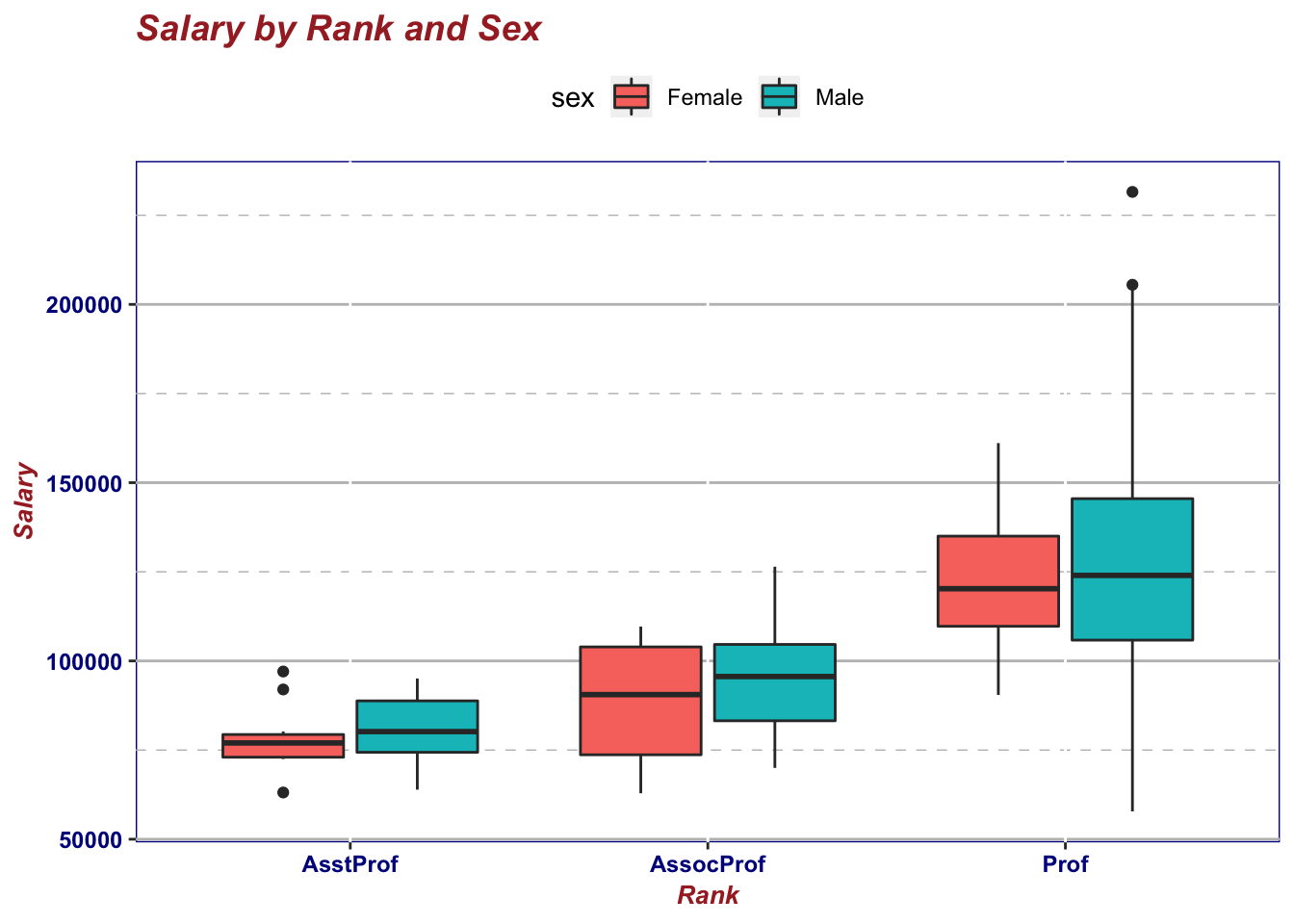 The theme,
The theme, mytheme, specifies that plot titles should be printed in brown, 14-point, bold italics; axis titles should be printed in brown, 10-point, bold italics; axis labels should be printed in dark blue, 9-point bold; the plot area should have a white fill and dark blue borders; major horizontal grids should be gray solid lines; minor horizontal grids should be grey dashed lines; vertical grids should be suppressed; and the legend should appear at the top of the graph. The theme() function gives you great control over the look of the finished product. See help(theme) to learn more about these options.
12.6.5 Multiple graphs per page
In section 3.5, you used the graphic parameter mfrow and the base function layout() to combine two or more base graphs into a single plot. Again, this approach won’t work with plots created with the ggplot2 package. The easiest way to place multiple ggplot2 graphs in a single figure is to use the grid.arrange() function in the gridExtra package.
Let’s create three ggplot2 graphs and place them in a single graph. The code is given in the following listing:
data(Salaries, package="car")
library(ggplot2)
library(gridExtra)
p1 <- ggplot(data=Salaries, aes(x=rank)) + geom_bar()
p2 <- ggplot(data=Salaries, aes(x=sex)) + geom_bar()
p3 <- ggplot(data=Salaries, aes(x=yrs.since.phd, y=salary)) + geom_point()
grid.arrange(p1, p2, p3, ncol=3)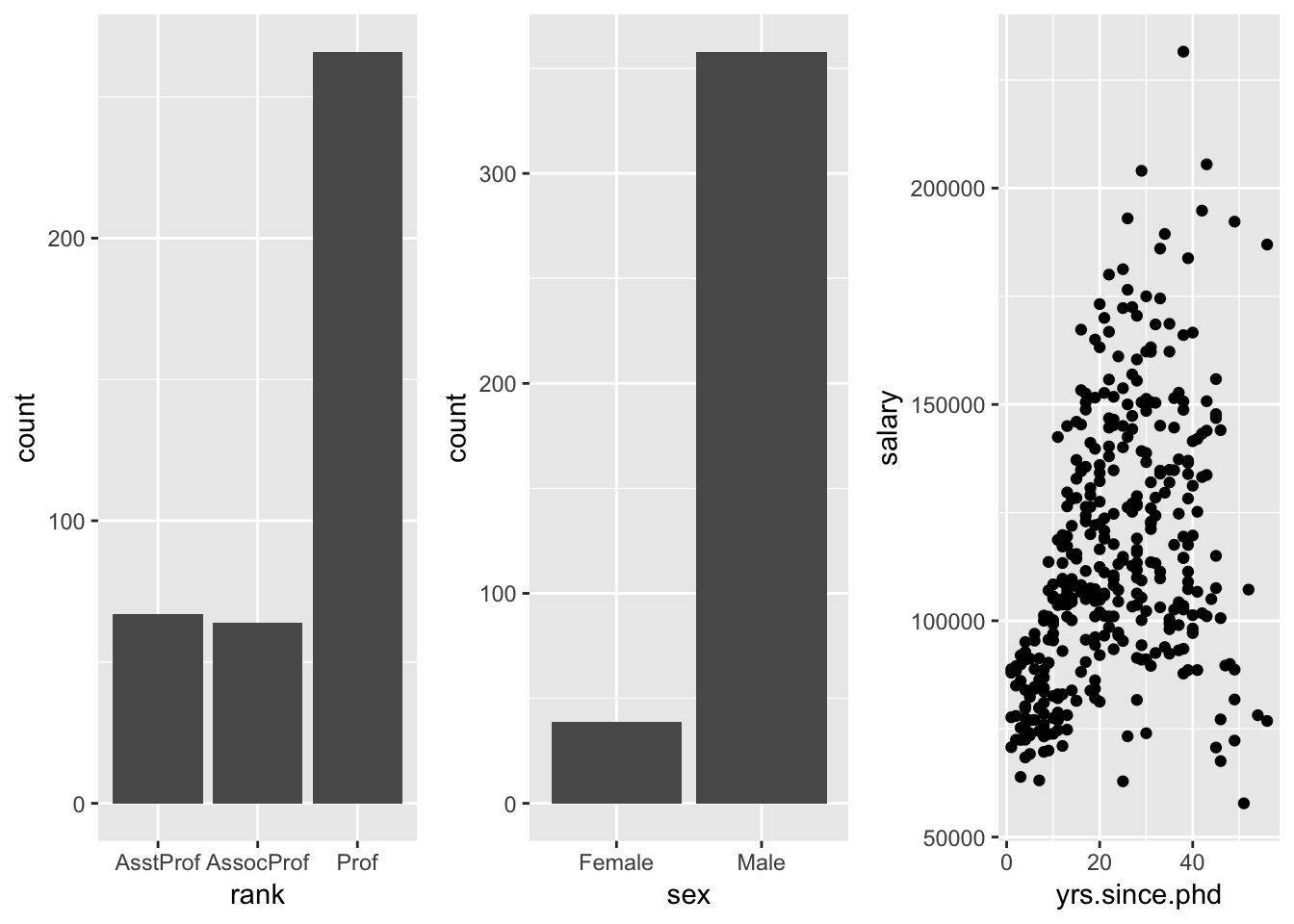 Each graph is saved as an object and then arranged into a single plot with the
Each graph is saved as an object and then arranged into a single plot with the grid.arrange() function.
Note the difference between faceting and multiple graphs. Faceting creates an array of plots based on one or more categorical variables. In this section, you’re arranging completely independent plots into a single graph.
12.6.6 Saving graphs
You can save the graphs created by ggplot2 using the standard methods discussed before. But a convenience function named ggsave() can be particularly useful. Options include which plot to save, where to save it, and in what format. For example,
myplot <- ggplot(data=mtcars, aes(x=mpg)) + geom_histogram()
ggsave(file="mygraph.png", plot=myplot, width=5, height=4)## `stat_bin()` using `bins = 30`. Pick better value with `binwidth`.saves myplot as a 5-inch by 4-inch PNG file named mygraph.png in the current working directory. You can save the graph in a different format by setting the file extension to ps, tex, jpeg, pdf, jpeg, tiff, png, bmp, svg, or wmf. The wmf format is only available on Windows machines.
If you omit the plot= option, the most recently created graph is saved. The code
ggplot(data=mtcars, aes(x=mpg)) + geom_histogram()## `stat_bin()` using `bins = 30`. Pick better value with `binwidth`.
ggsave(file="mygraph.pdf")## Saving 7 x 5 in image
## `stat_bin()` using `bins = 30`. Pick better value with `binwidth`.is valid and saves the graph to disk. See help(ggsave) for additional details.
12.6.7 Summary
This chapter reviewed the ggplot2 package, which provides advanced graphical methods based on a comprehensive grammar of graphics. The package is designed to provide you with a complete and comprehensive alternative to the native graphics provided with R. It offers methods for creating attractive and meaningful visualizations of data that are difficult to generate in other ways.
The ggplot2 package can be difficult to learn, but a wealth of material is available to help you on your journey:
A list of all
ggplot2functions, along with examples, can be found at http://docs.ggplot2.org.To learn about the theory underlying
ggplot2, see the original book by Wickham (2009).Finally, Chang (2013) has written a very practical book, chock full of useful examples. Chang’s book is definitely where I would start.
You should now have a firm grasp of the many ways that R allows you to create visual representations of data. If a picture is worth a thousand words, and R provides a thousand ways to create a picture, then R must be worth a million words (or something to that effect).